| Dec 2021 |
Our work Self-attentive 3D human pose and shape estimation from videos was published in Computer Vision and Image Understanding (Vol. 213), with Yun-Chun Chen, Robinson Piramuthu, and Ming-Hsuan Yang. |
| Dec 2018 |
The work on Manifold Learning for Left Ventricular Diastolic Dysfunction has been accepted as moderated poster at ACC 19. |
| Oct 2018 |
I was a volunteer at the CHOICE Heart Health screening event. |
| Apr 2018 |
I started working as a researcher at Heart and Vascular Institute. |
| Dec 2017 |
I defended successfully my dissertation on machine learning approaches for human body shape analysis. |
| Oct 2017 |
I'll be presenting our poster on Unified Deep Supervised Domain Adaptation and Generalization at ICCV2017. |
| Jun 2016 |
I attended CVPR 2016 in Las Vegas, NV.
We presented our work on: Information Bottleneck Learning Using Privileged Information for Visual Recognition with my colleague Saeid Motiian.
|
| May 2016 |
I attended the IEEE SPS Summer School on Signal Processing and Machine Learning for Big Data, Pittsburgh, PA. |
| July 2015 |
I attended the ICVSS15 International Computer Vision Summer School, Sicily Italy.
Organized by Roberto Cipolla, Sebastiano Battiato, and Giovanni Maria Farinella.
Mentored by Marc Pollefeys
|
| Dec 2011 |
I attended IJCB 2011 in Washington DC
We presented our work:"Can facial metrology predict gender?" with Arun Ross, T. Bourlai, and Donald Adjeroh
|
| Dec 2010 |
Our work: Predictability and correlation in human metrology, with Arun Ross and Donald Adjeroh has been presented at WIFS
|
|
| 2019 - 2024 |
eBay
Research Scientist
|
| April 2018 - 2019 |
Heart and Vascular Institute, School of Medicine, West Virginia University
Researcher
Machine learning and computer vision for Cardiovascular imaging.
|
| Aug 2017 - Dec 2017 |
Heart and Vascular Institute, School of Medicine, West Virginia University
Graduate Assistant.
Machine learning and computer vision for Cardiovascular imaging.
|
| Jan 2010 - May 2018 |
West Virginia University, Gianfranco Doretto, Donald Adjeroh
Machine learning, computer vision, biometrics
|
| June 2013 - May 2014 |
Center for Identification Technology Research, Co-PI
Mobile Structured Light System for 3D Face Acquisition.
|
| June 2010 - May 2012 |
Center for Identification Technology Research, Arun Ross, Bojan Cukic
Night Biometrics project funded by ONR’s Green Devil II initiative
|
| Aug 2008 - Dec 2008 |
West Virginia University, Xin Li, Donald Adjeroh
Visiting Student
Segmentation of vessels structures, and macular retinopathy in retinal images.
|
| Apr 2007 - Dec 2009 |
Department of Information Engineering (DEI), Padua Univ., Giancarlo Calvagno
Distribuited Video Coding with Continuous-Value Syndromes,
Segmentation of vessels structures, and macular retinopathy in retinal images.
|
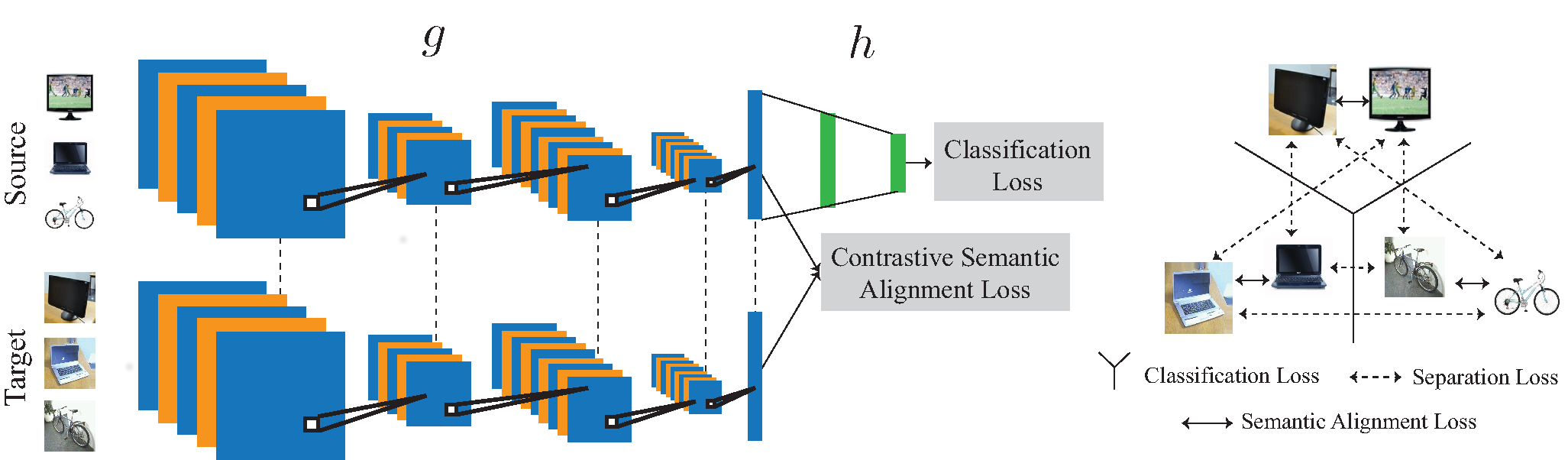 |
Unified Deep Supervised Domain Adaptation and Generalization
S. Motiian, M. Piccirilli, D. A. Adjeroh, G. Doretto
ICCV 2017
[1]
[abs] [pdf] [web]
This work provides a unified framework for addressing the problem of visual supervised domain adaptation and generalization with deep models. The main idea is to exploit the Siamese architecture to learn an embedding subspace that is discriminative, and where mapped visual domains are semantically aligned and yet maximally separated. The supervised setting becomes attractive especially when only few target data samples need to be labeled. In this scenario, alignment and separation of semantic probability distributions is difficult because of the lack of data. We found that by reverting to point-wise surrogates of distribution distances and similarities provides an effective solution. In addition, the approach has a high speed of adaptation, which requires an extremely low number of labeled target training samples, even one per category can be effective. The approach is extended to domain generalization. For both applications the experiments show very promising results.
|
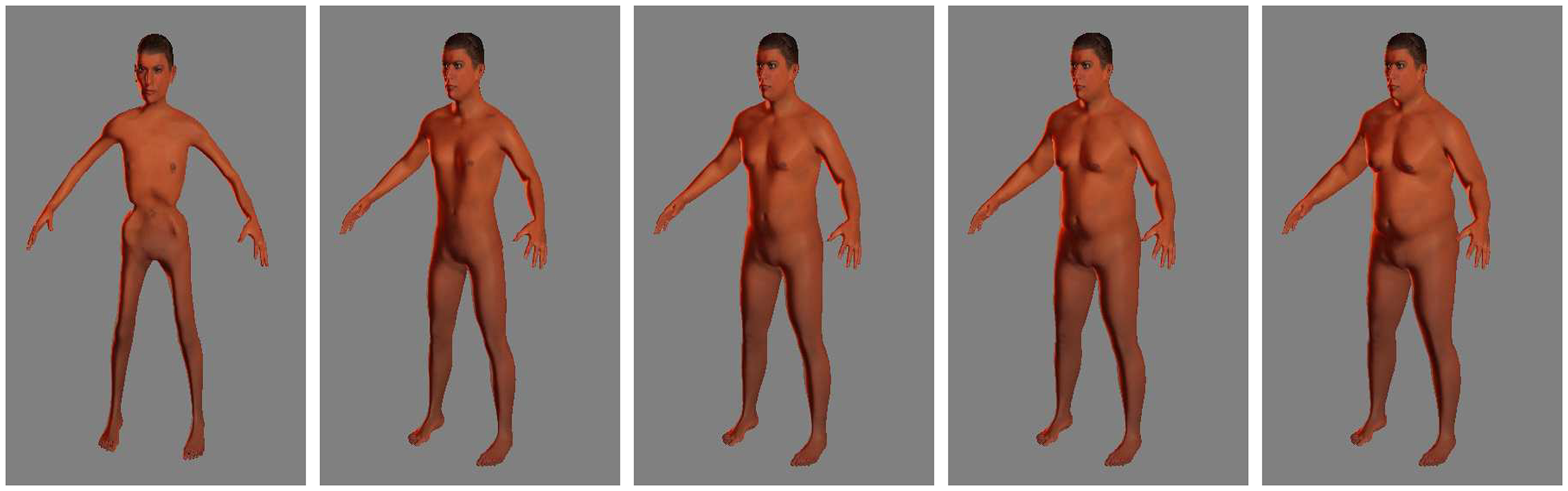 |
A Framework for Analyzing the Whole Body Surface Area from a Single View
M. Piccirilli, G. Doretto, D.A. Adjeroh
PLOS One 2017
[2]
[abs] [pdf] [blog1] [blog2]
We present a virtual reality (VR) framework for the analysis of whole human body surface area. Usual methods for determining the whole body surface area (WBSA) are based on well known formulae, characterized by large errors when the subject is obese, or belongs to certain subgroups. For these situations, we believe that a computer vision approach can overcome these problems and provide a better estimate of this important body indicator. Unfortunately, using machine learning techniques to design a computer vision system able to provide a new body indicator that goes beyond the use of only body weight and height, entails a long and expensive data acquisition process. A more viable solution is to use a dataset composed of virtual subjects. Generating a virtual dataset allowed us to build a population with different characteristics (obese, underweight, age, gender). However, synthetic data might differ from a real scenario, typical of the physician’s clinic. For this reason we develop a new virtual environment to facilitate the analysis of human subjects in 3D. This framework can simulate the acquisition process of a real camera, making it easy to analyze and to create training data for machine learning algorithms. With this virtual environment, we can easily simulate the real setup of a clinic, where a subject is standing in front of a camera, or may assume a different pose with respect to the camera. We use this newly designated environment to analyze the whole body surface area (WBSA). In particular, we show that we can obtain accurate WBSA estimations with just one view, virtually enabling the possibility to use inexpensive depth sensors (e.g., the Kinect) for large scale quantification of the WBSA from a single view 3D map.
|
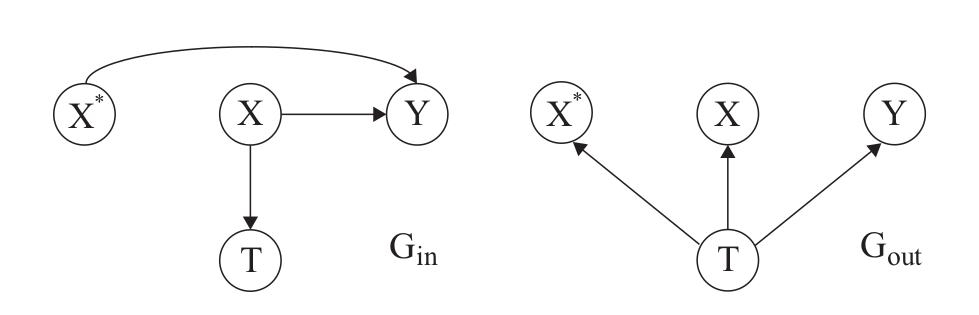 |
Information Bottleneck Learning Using Privileged Information for Visual Recognition
S. Motiian M. Piccirilli D. A. Adjeroh G. Doretto
CVPR 2016
[3]
[abs] [pdf]
We explore the visual recognition problem from a main
data view when an auxiliary data view is available during
training. This is important because it allows improving the
training of visual classifiers when paired additional data
is cheaply available, and it improves the recognition from
multi-view data when there is a missing view at testing time.
The problem is challenging because of the intrinsic asymmetry
caused by the missing auxiliary view during testing.
We account for such view during training by extending the
information bottleneck method, and by combining it with
risk minimization. In this way, we establish an information
theoretic principle for leaning any type of visual classifier
under this particular setting. We use this principle to design
a large-margin classifier with an efficient optimization in
the primal space. We extensively compare our method with
the state-of-the-art on different visual recognition datasets,
and with different types of auxiliary data, and show that the
proposed framework has a very promising potential.
|
 |
A Mobile Structured Light System for 3D Face Acquisition
M. Piccirilli, G. Doretto, A. Ross, D.A. Adjeroh
IEEE SENSORS JOURNAL Apr. 2016
[4]
[abs] [pdf] [blog]
A mobile sensor based on fringe projection
techniques is developed with the goal of acquiring face 3D
and color with a smartphone device. The system consists of a
portable pico-projector and an Android-based smartphone. The
data acquisition, pattern generation. and reconstruction of the
final 3D point cloud are all driven by the smartphone. We present
results on the root-mean-square error (RMSE) of the sensor and
on 3D face matching.
|
 |
Predictability and correlation in human metrology
D. Adjeroh, D. Cao, M. Piccirilli, A. Ross
WIFS 2010
[5]
[abs] [pdf]
Human metrology provides an important soft bio-metric, which can be used in challenging situations such as human identification at a distance, when traditional biometric traits such as fingerprints or iris cannot be easily acquired. We study the problem of predictability and correlation in human metrology, using the tools of uncertainty and differential entropy. We show that while various metrological features are highly correlated with each other, there exists some correlation clusters in human metrology, whereby measurements in a cluster tend to be highly correlated with each other but not with the others. Based on these clusters, we propose a two-step approach for predicting unknown body measurements. Using the same framework, we study the problem of estimating other soft biometrics such as weight and gender.
|
| |
Unified Deep Supervised Domain Adaptation and Generalization
S. Motiian, M. Piccirilli, D. A. Adjeroh, G. Doretto
ICCV 2017
[C1]
[abs] [pdf] [web]
This work provides a unified framework for addressing the problem of visual supervised domain adaptation and generalization with deep models. The main idea is to exploit the Siamese architecture to learn an embedding subspace that is discriminative, and where mapped visual domains are semantically aligned and yet maximally separated. The supervised setting becomes attractive especially when only few target data samples need to be labeled. In this scenario, alignment and separation of semantic probability distributions is difficult because of the lack of data. We found that by reverting to point-wise surrogates of distribution distances and similarities provides an effective solution. In addition, the approach has a high speed of adaptation, which requires an extremely low number of labeled target training samples, even one per category can be effective. The approach is extended to domain generalization. For both applications the experiments show very promising results.
|
| |
Information Bottleneck Learning Using Privileged Information for Visual Recognition
S. Motiian M. Piccirilli D. A. Adjeroh G. Doretto
CVPR 2016
[C2]
[abs] [pdf]
We explore the visual recognition problem from a main
data view when an auxiliary data view is available during
training. This is important because it allows improving the
training of visual classifiers when paired additional data
is cheaply available, and it improves the recognition from
multi-view data when there is a missing view at testing time.
The problem is challenging because of the intrinsic asymmetry
caused by the missing auxiliary view during testing.
We account for such view during training by extending the
information bottleneck method, and by combining it with
risk minimization. In this way, we establish an information
theoretic principle for leaning any type of visual classifier
under this particular setting. We use this principle to design
a large-margin classifier with an efficient optimization in
the primal space. We extensively compare our method with
the state-of-the-art on different visual recognition datasets,
and with different types of auxiliary data, and show that the
proposed framework has a very promising potential.
|
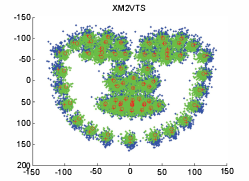 |
"Can facial metrology predict gender?"
D. Cao, C. Chen, M. Piccirilli, D. Adjeroh, T. Bourlai, and A. Ross.
IJCB
[C3]
[abs] [pdf]
We investigate the question of whether facial metrology can be exploited for reliable gender prediction. A new method based solely on metrological information from facial landmarks is developed. Here, metrological features are defined in terms of specially normalized angle and distance measures and computed based on given landmarks on facial images. The performance of the proposed metrology- based method is compared with that of a state-of-the-art appearance-based method for gender classification. Results are reported on two standard face databases, namely, MUCT and XM2VTS containing 276 and 295 images, respectively. The performance of the metrology-based approach was slightly lower than that of the appearance- based method by only about 3.8% for the MUCT database and about 5.7% for the XM2VTS database.
|
| |
Predictability and correlation in human metrology
D. Adjeroh, D. Cao, M. Piccirilli, A. Ross
WIFS 2010
[C4]
[abs] [pdf]
Human metrology provides an important soft bio-metric, which can be used in challenging situations such as human identification at a distance, when traditional biometric traits such as fingerprints or iris cannot be easily acquired. We study the problem of predictability and correlation in human metrology, using the tools of uncertainty and differential entropy. We show that while various metrological features are highly correlated with each other, there exists some correlation clusters in human metrology, whereby measurements in a cluster tend to be highly correlated with each other but not with the others. Based on these clusters, we propose a two-step approach for predicting unknown body measurements. Using the same framework, we study the problem of estimating other soft biometrics such as weight and gender.
|
| |
A Framework for Analyzing the Whole Body Surface Area from a Single View
M. Piccirilli, G. Doretto, D.A. Adjeroh
PLOS One 2017
[J1]
[abs] [pdf]
We present a virtual reality (VR) framework for the analysis of whole human body surface area. Usual methods for determining the whole body surface area (WBSA) are based on well known formulae, characterized by large errors when the subject is obese, or belongs to certain subgroups. For these situations, we believe that a computer vision approach can overcome these problems and provide a better estimate of this important body indicator. Unfortunately, using machine learning techniques to design a computer vision system able to provide a new body indicator that goes beyond the use of only body weight and height, entails a long and expensive data acquisition process. A more viable solution is to use a dataset composed of virtual subjects. Generating a virtual dataset allowed us to build a population with different characteristics (obese, underweight, age, gender). However, synthetic data might differ from a real scenario, typical of the physician’s clinic. For this reason we develop a new virtual environment to facilitate the analysis of human subjects in 3D. This framework can simulate the acquisition process of a real camera, making it easy to analyze and to create training data for machine learning algorithms. With this virtual environment, we can easily simulate the real setup of a clinic, where a subject is standing in front of a camera, or may assume a different pose with respect to the camera. We use this newly designated environment to analyze the whole body surface area (WBSA). In particular, we show that we can obtain accurate WBSA estimations with just one view, virtually enabling the possibility to use inexpensive depth sensors (e.g., the Kinect) for large scale quantification of the WBSA from a single view 3D map.
|
| |
A Mobile Structured Light System for 3D Face Acquisition
M. Piccirilli, G. Doretto, A. Ross, D.A. Adjeroh
IEEE SENSORS JOURNAL Apr. 2016
[J2]
[abs] [pdf]
A mobile sensor based on fringe projection
techniques is developed with the goal of acquiring face 3D
and color with a smartphone device. The system consists of a
portable pico-projector and an Android-based smartphone. The
data acquisition, pattern generation. and reconstruction of the
final 3D point cloud are all driven by the smartphone. We present
results on the root-mean-square error (RMSE) of the sensor and
on 3D face matching.
|
 Marco Piccirilli
Marco Piccirilli